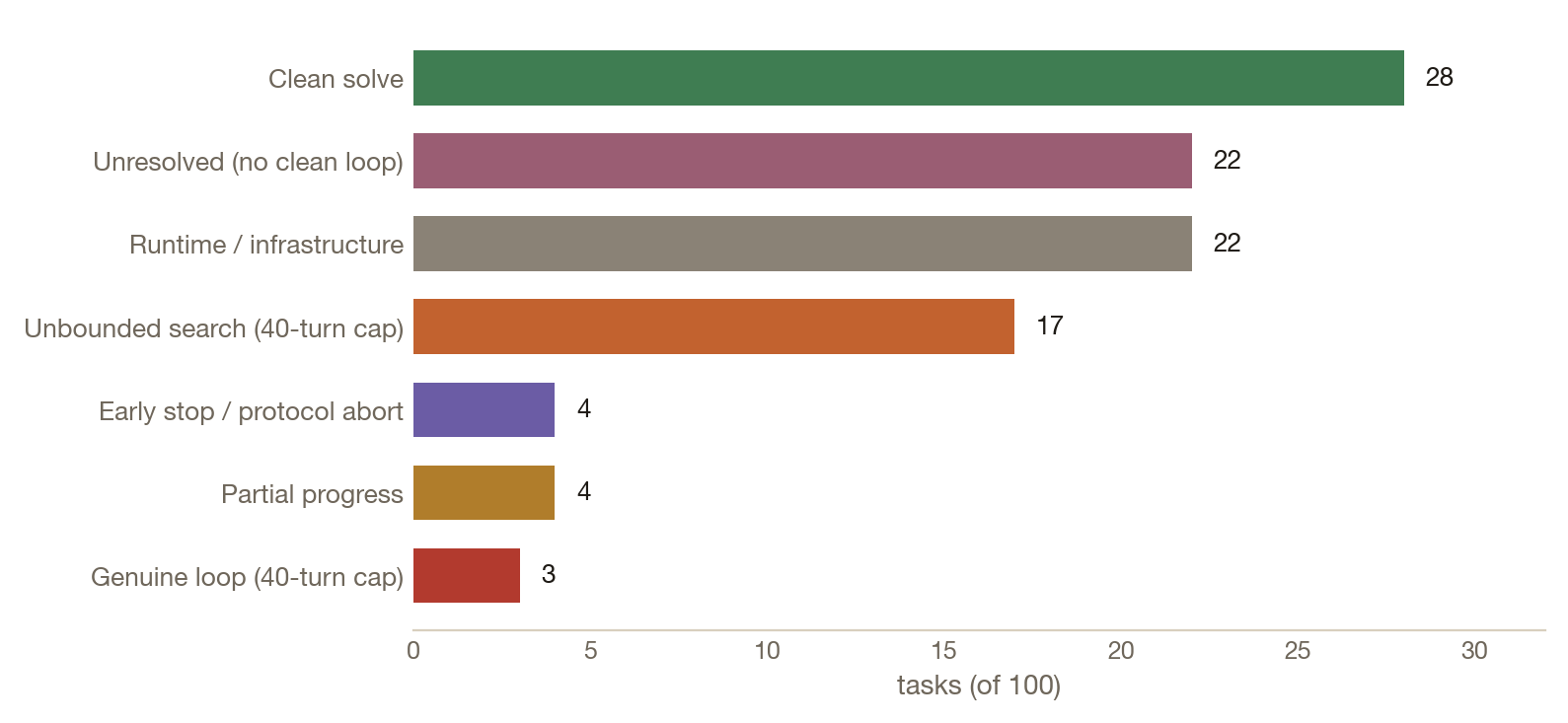
Clean solve 28 tasks
Inspect, build, verify, clean stop. These runs show the latent skills are present.
amuse-install
score 1
19 turns
Solved in 19 turns with 17 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 18; unique commands: 17; dominant-action share: 11%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
anomaly-detection-ranking
score 1
29 turns
Solved in 29 turns with 28 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 28; unique commands: 28; dominant-action share: 4%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
auth_token_race_condition
score 1
5 turns
Solved in 5 turns with 3 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 4; unique commands: 3; dominant-action share: 50%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
basic-message-queue
score 1
35 turns
Solved in 35 turns with 31 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 34; unique commands: 31; dominant-action share: 9%.
- adjacent exact repeats: 1; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
broken-python
score 1
15 turns
Solved in 15 turns with 14 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 14; unique commands: 14; dominant-action share: 7%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
california-housing-api
score 1
26 turns
Solved in 26 turns with 25 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 25; unique commands: 25; dominant-action share: 4%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
chained-forensic-extraction_20260101_011957
score 1
23 turns
Solved in 23 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
convolutional-layers
score 1
13 turns
Solved in 13 turns with 12 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 12; unique commands: 12; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
csv-json-jsonl-merger
score 1
10 turns
Solved in 10 turns with 9 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 9; unique commands: 9; dominant-action share: 11%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
grpc-plant-position-server
score 1
12 turns
Solved in 12 turns with 10 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 11; unique commands: 10; dominant-action share: 18%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
iris-dataset-classification
score 1
6 turns
Solved in 6 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
jsonl-aggregator
score 1
5 turns
Solved in 5 turns with 4 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 4; unique commands: 4; dominant-action share: 25%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
log-summary
score 1
9 turns
Solved in 9 turns with 8 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 8; unique commands: 8; dominant-action share: 12%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
maven-slf4j-conflict
score 1
27 turns
Solved in 27 turns with 23 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 26; unique commands: 23; dominant-action share: 12%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
Solved in 12 turns with 11 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 11; unique commands: 11; dominant-action share: 9%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
mtls-cert-rotation
score 1
12 turns
Solved in 12 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
Solved in 5 turns with 4 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 4; unique commands: 4; dominant-action share: 25%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
prediction-model-evaluation
score 1
21 turns
Solved in 21 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
protein-sequence
score 1
9 turns
Solved in 9 turns with 7 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 8; unique commands: 7; dominant-action share: 25%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
raft-log-repair-concurrent-access
score 1
3 turns
Solved in 3 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
reproducibility-and-envsetup
score 1
30 turns
Solved in 30 turns with 25 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 29; unique commands: 25; dominant-action share: 7%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
Solved in 13 turns with 12 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 12; unique commands: 12; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
sign-vector-game
score 1
18 turns
Solved in 18 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
Solved in 28 turns with 26 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 27; unique commands: 26; dominant-action share: 7%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
smiles-data-lab
score 1
13 turns
Solved in 13 turns with 12 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 12; unique commands: 12; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
sql-injection-forensics
score 1
8 turns
Solved in 8 turns with 0 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
submission_a63937a5_20251224_152124
score 1
23 turns
Solved in 23 turns with 21 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 22; unique commands: 21; dominant-action share: 9%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
sympy-bug-fix
score 1
40 turns
Solved in 40 turns with 40 unique commands. This is the positive-control behavior: execution skill is present when the task stays inside Laguna's closed-loop control envelope.
- tool calls: 40; unique commands: 40; dominant-action share: 2%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Positive sample for capability expression: inspect / execute / verify / stop can succeed under native tool calling.
Partial progress 4 tasks
Verifier gives partial credit: useful curriculum material if the missing checks are explicit.
tsl-test-case-generation
score 0.780
40 turns
Partial verifier reward 0.780 in 40 turns. This is high-value curriculum material because the trace likely contains real progress plus a missing final verification, edge-case check, or completion criterion.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Likely useful for process reward design: partial state is observable and verifier-scored.
Partial verifier reward 0.747 in 33 turns. This is high-value curriculum material because the trace likely contains real progress plus a missing final verification, edge-case check, or completion criterion.
- tool calls: 32; unique commands: 28; dominant-action share: 9%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Likely useful for process reward design: partial state is observable and verifier-scored.
security-incident-log-analysis
score 0.692
11 turns
Partial verifier reward 0.692 in 11 turns. This is high-value curriculum material because the trace likely contains real progress plus a missing final verification, edge-case check, or completion criterion.
- tool calls: 10; unique commands: 10; dominant-action share: 10%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Likely useful for process reward design: partial state is observable and verifier-scored.
security-breach-incident-response
score 0.683
17 turns
Partial verifier reward 0.683 in 17 turns. This is high-value curriculum material because the trace likely contains real progress plus a missing final verification, edge-case check, or completion criterion.
- tool calls: 16; unique commands: 16; dominant-action share: 6%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Likely useful for process reward design: partial state is observable and verifier-scored.
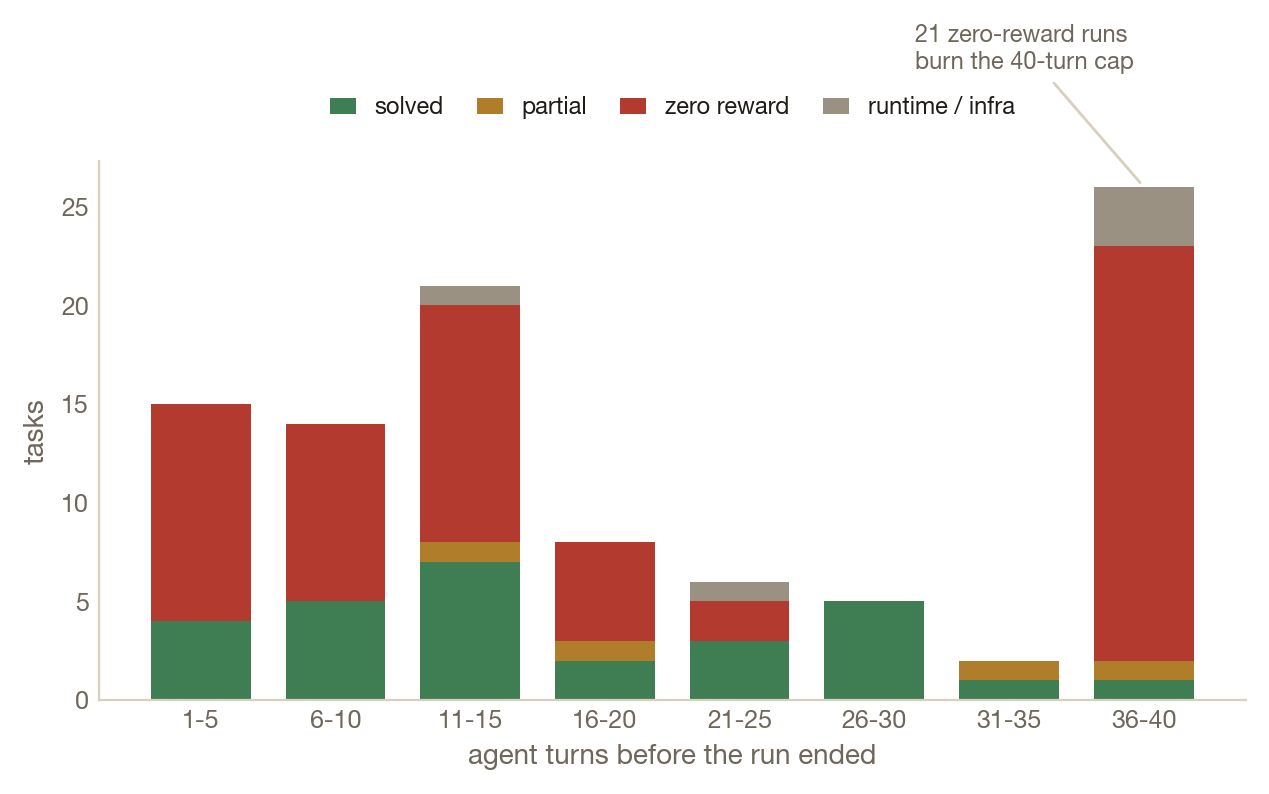
Genuine loop (40-turn cap) 3 tasks
Burns the turn cap with repeated or near-repeated actions; the recognition-to-action coupling target.
bracket-sequence-restoration
score 0
40 turns
Zero reward after 40 turns. The dominant action accounts for 50% of tool calls with 0 adjacent exact repeats, so the failure is action inertia under stale evidence rather than missing atomic terminal skill.
- tool calls: 40; unique commands: 4; dominant-action share: 50%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: couple stuck recognition to a changed action or an explicit stop decision.
pdf-table-parsing
score 0
40 turns
Zero reward after 40 turns. The dominant action accounts for 75% of tool calls with 29 adjacent exact repeats, so the failure is action inertia under stale evidence rather than missing atomic terminal skill.
- tool calls: 40; unique commands: 11; dominant-action share: 75%.
- adjacent exact repeats: 29; assistant turns without tool calls: 0.
- Primary RL target: couple stuck recognition to a changed action or an explicit stop decision.
Zero reward after 40 turns. The dominant action accounts for 75% of tool calls with 29 adjacent exact repeats, so the failure is action inertia under stale evidence rather than missing atomic terminal skill.
- tool calls: 40; unique commands: 11; dominant-action share: 75%.
- adjacent exact repeats: 29; assistant turns without tool calls: 0.
- Primary RL target: couple stuck recognition to a changed action or an explicit stop decision.
Unbounded search (40-turn cap) 17 tasks
Uses the whole budget without enough repetition to be a pure loop; progress-ledger and search-discipline target.
acl-permissions-inheritance
score 0
40 turns
Zero reward at the turn cap with 40 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 40; dominant-action share: 2%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
api-endpoint-permission-canonicalizer
score 0
40 turns
Zero reward at the turn cap with 26 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 26; dominant-action share: 35%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
Zero reward at the turn cap with 13 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 13; dominant-action share: 28%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
corrupted-filesystem-recovery
score 0
40 turns
Zero reward at the turn cap with 0 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
cpp-daemon-sighup-segfault
score 0
40 turns
Zero reward at the turn cap with 23 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 23; dominant-action share: 28%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
Zero reward at the turn cap with 31 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 31; dominant-action share: 18%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
floor-plan-geometry
score 0
40 turns
Zero reward at the turn cap with 0 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
game-of-stones
score 0
40 turns
Zero reward at the turn cap with 0 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
git-repo-forensics
score 0
40 turns
Zero reward at the turn cap with 39 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 39; dominant-action share: 5%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
multi-server-configuration
score 0
40 turns
Zero reward at the turn cap with 38 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 38; dominant-action share: 5%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
parking-lot-pathfinding
score 0
40 turns
Zero reward at the turn cap with 40 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 40; dominant-action share: 2%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
playing-card-recognition
score 0
40 turns
Zero reward at the turn cap with 0 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
publisher-market-analysis
score 0
40 turns
Zero reward at the turn cap with 0 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
react-typescript-debugg
score 0
40 turns
Zero reward at the turn cap with 39 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 39; dominant-action share: 5%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
symlink-chain-traversal
score 0
40 turns
Zero reward at the turn cap with 34 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 34; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
systemd-log-monitoring
score 0
40 turns
Zero reward at the turn cap with 37 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 40; unique commands: 37; dominant-action share: 10%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
token-auth-websocket
score 0
40 turns
Zero reward at the turn cap with 0 unique commands. This looks less like a byte-identical loop and more like unbounded search without a maintained progress ledger.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: bounded search with progress accounting, not just more exploration.
Early stop / protocol abort 4 tasks
Stops or aborts too early; stop-quality and tool-call robustness target.
Zero reward after only 2 turns. Treat as stop-quality or protocol-abort evidence until the raw trace proves it was a genuine task-level decision.
- tool calls: 1; unique commands: 1; dominant-action share: 100%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Primary RL target: stop only after deliverable verification; separate policy early stops from harness/runtime aborts.
hydra-debug-slurm-mode
score 0
1 turns
Zero reward after only 1 turns. Treat as stop-quality or protocol-abort evidence until the raw trace proves it was a genuine task-level decision.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: stop only after deliverable verification; separate policy early stops from harness/runtime aborts.
multi-labeller
score 0
3 turns
Zero reward after only 3 turns. Treat as stop-quality or protocol-abort evidence until the raw trace proves it was a genuine task-level decision.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Primary RL target: stop only after deliverable verification; separate policy early stops from harness/runtime aborts.
todos-api
score 0
3 turns
Zero reward after only 3 turns. Treat as stop-quality or protocol-abort evidence until the raw trace proves it was a genuine task-level decision.
- tool calls: 2; unique commands: 2; dominant-action share: 50%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Primary RL target: stop only after deliverable verification; separate policy early stops from harness/runtime aborts.
Runtime / infrastructure 22 tasks
Trial or runtime exceptions; useful for harness triage, not model-behavior claims.
breast-cancer-mlflow
score 0
15 turns
Trial produced no clean behavioral verdict after 15 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
container-registry-optimization
score n/a
0 turns
Trial produced no clean behavioral verdict after 0 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
cosign-keyless-signing
score 0
17 turns
Trial produced no clean behavioral verdict after 17 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
ekf-localization
score 0
38 turns
Trial produced no clean behavioral verdict after 38 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 38; unique commands: 11; dominant-action share: 74%.
- adjacent exact repeats: 27; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
etl_checkpoint_resume_bug
score n/a
0 turns
Trial produced no clean behavioral verdict after 0 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
fix-js-network-controller
score 0
5 turns
Trial produced no clean behavioral verdict after 5 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
grid-pathfinding
score 0
15 turns
Trial produced no clean behavioral verdict after 15 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 15; unique commands: 14; dominant-action share: 13%.
- adjacent exact repeats: 1; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
image-tile-identification
score n/a
22 turns
Trial produced no clean behavioral verdict after 22 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
legal-summary-extraction
score n/a
94 turns
Trial produced no clean behavioral verdict after 94 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
mech-system
score 0
10 turns
Trial produced no clean behavioral verdict after 10 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
monorepo-changelog-cli
score 0
11 turns
Trial produced no clean behavioral verdict after 11 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
network-log-normalization
score n/a
0 turns
Trial produced no clean behavioral verdict after 0 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
Trial produced no clean behavioral verdict after 13 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 13; unique commands: 13; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
permutation-construction-100k
score 0
12 turns
Trial produced no clean behavioral verdict after 12 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 12; unique commands: 12; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
publisher-market-analysis-v2
score n/a
64 turns
Trial produced no clean behavioral verdict after 64 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
python-api-rate-limit
score 0
12 turns
Trial produced no clean behavioral verdict after 12 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
reverse-engineer-stack-vm
score 0
5 turns
Trial produced no clean behavioral verdict after 5 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
rsa-jwt-token-api-redis-blacklist
score 0
16 turns
Trial produced no clean behavioral verdict after 16 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
scan-linux-persistence-artifacts
score 0
12 turns
Trial produced no clean behavioral verdict after 12 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
task-xxe-exploit
score 0
6 turns
Trial produced no clean behavioral verdict after 6 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
vimscript-vim-quine
score 0
10 turns
Trial produced no clean behavioral verdict after 10 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 10; unique commands: 10; dominant-action share: 10%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
word-derangement-mapping
score n/a
48 turns
Trial produced no clean behavioral verdict after 48 turns. Exception head: Traceback (most recent call last): Keep out of training and evaluation claims unless a rerun succeeds.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Exclude from reward-variance estimates until rerun; this is not clean model-behavior evidence.
Unresolved (no clean loop) 22 tasks
Zero reward before the cap without a clean loop signature; adjacent capability expression target.
application-debug
score 0
18 turns
Zero reward after 18 turns with 15 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 17; unique commands: 15; dominant-action share: 12%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
bandit-delayed-feedback
score 0
8 turns
Zero reward after 8 turns with 7 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 7; unique commands: 7; dominant-action share: 14%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
battery-charging-optimization
score 0
4 turns
Zero reward after 4 turns with 3 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 3; unique commands: 3; dominant-action share: 33%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
bloom-filter-cache-penetration-prevention
score 0
6 turns
Zero reward after 6 turns with 5 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 5; unique commands: 5; dominant-action share: 20%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
build-merkle-tree-cli-sha512
score 0
5 turns
Zero reward after 5 turns with 4 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 4; unique commands: 4; dominant-action share: 25%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
competitive-programming-solver
score 0
15 turns
Zero reward after 15 turns with 14 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 14; unique commands: 14; dominant-action share: 7%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
cryptographic-protocol-verifier
score 0
6 turns
Zero reward after 6 turns with 4 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 5; unique commands: 4; dominant-action share: 40%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
distributed-test-execution-scheduler
score 0
17 turns
Zero reward after 17 turns with 16 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 16; unique commands: 16; dominant-action share: 6%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
fix_async_worker_queue
score 0
13 turns
Zero reward after 13 turns with 0 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 0; unique commands: 0; dominant-action share: 0%.
- adjacent exact repeats: 0; assistant turns without tool calls: 0.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
html-index-analysis
score 0
5 turns
Zero reward after 5 turns with 4 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 4; unique commands: 4; dominant-action share: 25%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
industrial-kiln-controller
score 0
21 turns
Zero reward after 21 turns with 20 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 20; unique commands: 20; dominant-action share: 5%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
iot-device-registration-server
score 0
25 turns
Zero reward after 25 turns with 22 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 24; unique commands: 22; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
Zero reward after 15 turns with 14 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 14; unique commands: 14; dominant-action share: 7%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
malicious-package-forensics
score 0
14 turns
Zero reward after 14 turns with 13 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 13; unique commands: 13; dominant-action share: 8%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
neural-architecture-search-final
score 0
6 turns
Zero reward after 6 turns with 5 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 5; unique commands: 5; dominant-action share: 20%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
neutron-submission
score 0
6 turns
Zero reward after 6 turns with 5 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 5; unique commands: 5; dominant-action share: 20%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
pandas-etl
score 0
12 turns
Zero reward after 12 turns with 8 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 11; unique commands: 8; dominant-action share: 36%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
sakila-sqlite-queries
score 0
20 turns
Zero reward after 20 turns with 17 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 19; unique commands: 17; dominant-action share: 11%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
sales-data-csv-analysis
score 0
4 turns
Zero reward after 4 turns with 3 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 3; unique commands: 3; dominant-action share: 33%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
server-log-analysis
score 0
4 turns
Zero reward after 4 turns with 3 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 3; unique commands: 3; dominant-action share: 33%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
service-deployment-wave-planner
score 0
7 turns
Zero reward after 7 turns with 6 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 6; unique commands: 6; dominant-action share: 17%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.
supply-chain-fulfillment
score 0
11 turns
Zero reward after 11 turns with 10 unique commands. The failure is adjacent to capability expression: enough action diversity to avoid pure-loop labeling, but no verified deliverable.
- tool calls: 10; unique commands: 10; dominant-action share: 10%.
- adjacent exact repeats: 0; assistant turns without tool calls: 1.
- Use raw trace review to decide whether this is trainable-band weakness or true missing skill.